How we built Wavman
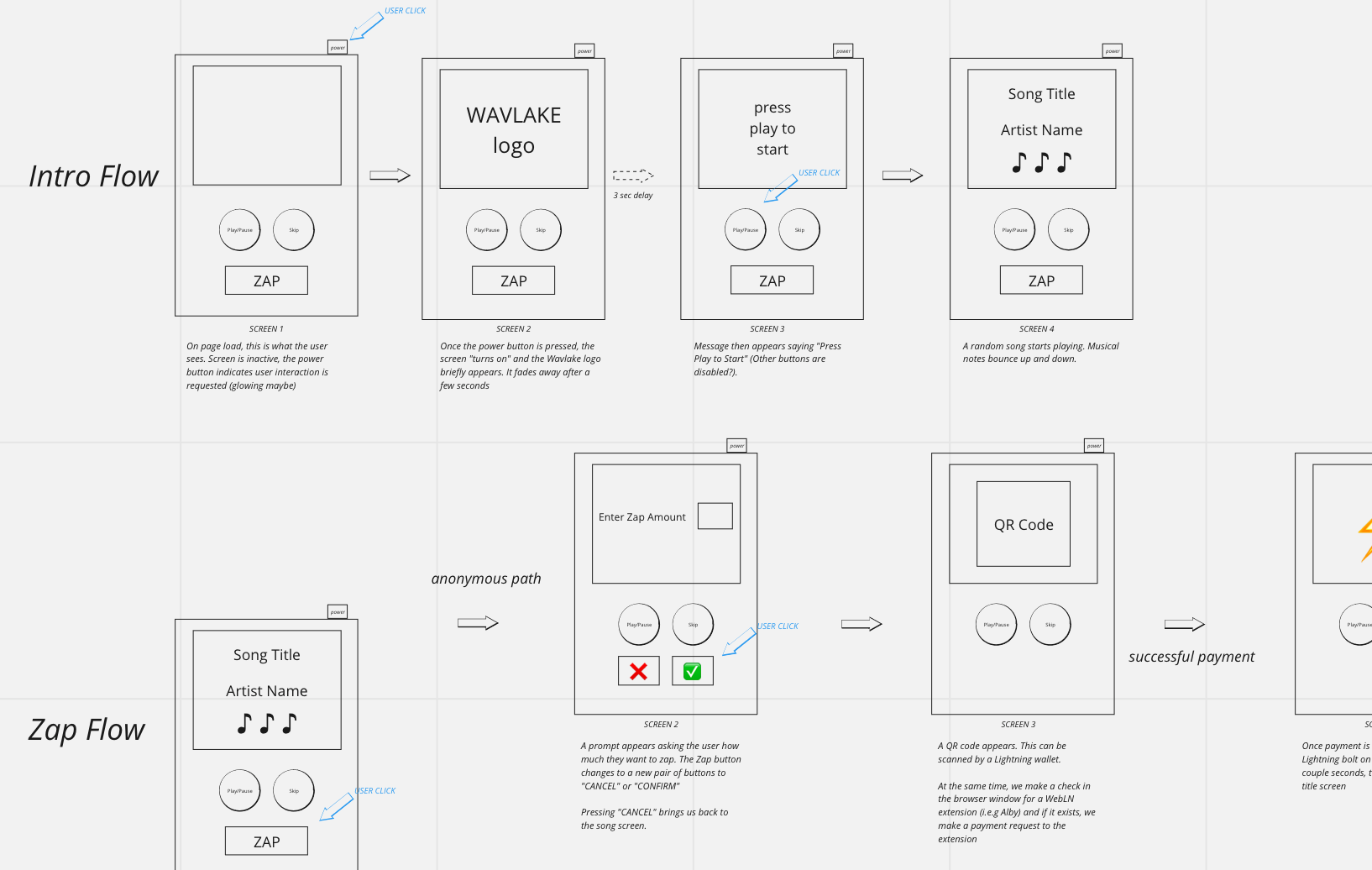
We think Nostr presents a great opportunity to build a new way to interact with music on the internet, which is why we decided to build Wavman. Wavman is a proof-of-concept/prototype that serves two main purposes. First, to explore the potential for interactive media on Nostr. Second, to help further innovation for these kinds of media applications moving forward.
Since there are no established ways for content such as music to be published or interacted with on Nostr, we had to make a few critical design decisions to fit our use case. The purpose of this article is to outline these decisions and explain why we chose to make them. Our hope is that we can help move the conversation forward by sharing with the community our thought process and rationale. To be clear: we do not hold any of these ideas strongly and offer them only as one approach for how we might handle these kinds of applications on Nostr in the future.
The NOM (Nostr Open Media) Spec
To start with, we needed a simple way to define a song. This definition needed to include basic metadata about the song: things like the title and artist. It also needed to include a pointer to where the media file for the song could be downloaded.
Additionally, the data had to allow a publisher to update and edit the metadata as needed. For example, if the location of the mp3 file for a song changed for some reason, the publisher would need the ability to broadcast that metadata update and replace the old definition of the song.
Taking some cues from podcasting, we fashioned a very minimal document, formatted like so:
{
"title": <string>, // Name of content
"guid": <string>, // Application-specific unique identifier
"creator": <string>, // Artist name
"type": <string>, // MIME type (example: "audio/mpeg")
"duration": <integer>, // Length of media in seconds
"published_at": <string>, // Unix timestamp converted to string
"link": <string>, // URL to hosting site for media (example: "https://mysite.com/my-song-page")
"enclosure": <string>, // URL to media content file (example: "https://cdn.com/mysong.mp3")
"version": <string>, // Schema version to maintain compatibility with clients
}
Keeping with the spirit of Nostr, the schema is intentionally lightweight and as obvious as possible. We've taken a few labels from podcasting, which has served it well for years. We've also followed the standard Nostr label and type for publish date to stay consistent.
The version element is there to ensure compatibility with clients while enabling incremental upgrades. The approach is similar to API versioning. In this case, any small additions could be treated as minor, non-breaking updates that clients could take advantage of when ready, whereas larger modifications could be treated as major, breaking changes that would require more effort for the client to start consuming.
So why not a new NIP?
The document described above is intended for the content field of a standard Nostr event. We chose to go this route because a new NIP, simply put, seemed like overkill. One of the greatest advantages of Nostr is the fact that the content in an event can be completely arbitrary. Today we mostly use it for things like messages and articles but it could just as easily support machine language or IoT data.

Another reason we chose this path is we think it will be faster to iterate on an open data model for media if it can be governed outside of the NIP process. This is not to suggest that particular process is unsatisfactory or flawed in any way. Rather, we think this type of application-specific use case does not require protocol-level approval and adoption.
Nostr already offers most, if not all, of the basic building blocks to construct these types of events. Exactly what the content of those events look like should only concern a subset of the broader Nostr developer community and it seems like those conversations would be more efficient if they happened in parallel to discussions regarding the protocol itself.
In our case, we decided to embed our NOM document in the content field of an application-specific event – kind 32123 – so that our client would be able to find our media events and parse them predictably. The kind value, 32123, falls within the range reserved for Parametrized Replaceable Events (NIP-33), which uses a key (the d tag) to identify a piece of media. This key, coupled with the public key of the publisher, can be used by clients to locate the most recent version of a media event.
For example, we could publish a kind 32123 event for a song called "Twinkle, Twinkle" and add a d value to that event of abcd-1234. Later, if we wanted to change the title to "Twinkle, Twinkle Little Star", we could simply republish the event with the new title and the same d value as before. Based on the publish date of the events, a client could easily identify the most recent version and serve that to the user.
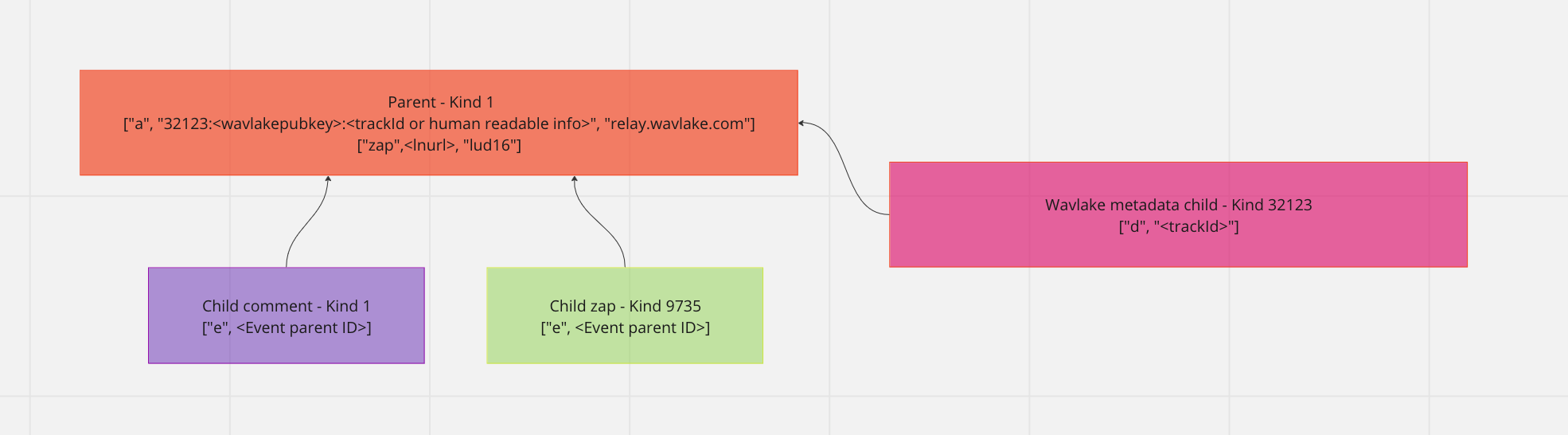
Cross-Compatibility
One challenge we anticipated is that most Nostr clients today have no idea what a 32123 event is. Nor should they! We just made it up, after all. But we did want these songs to be visible and engageable from anywhere.
So, we also created a standard kind 1 event for every track we published. This event is extremely basic: it just lists the artist and title for a song, then a link to its home page on wavlake.com. The one quirk is we added a reference to the 32123 event via the a tag. This enables any client to find these tracks and, if they like, present the media itself to a user by requesting the 32123 event and parsing the metadata.
This approach also allows a user on any Nostr client to zap a track note just like any other note, and those zaps will accrue to the note over time (Wavman itself zaps the kind 1 note as well). What we like about this is we can update any of the track's metadata if we need to but that kind 1 note can stay the same and keep accumulating zaps and comments, creating an ongoing record of interactions for the song. This opens up the possibility for creating rankings and charts for songs on Nostr based on public interactions and zaps – which means anyone could curate material based on this data. This is incredibly exciting.
One concern, however, is the inability to objectively prove a payment under the current NIP-57 scheme. This is not a major issue for zapping today but in the scenario described above, a scammer could create a bunch of fake payments in order to falsely boost the popularity of a song. In order to create a more honest signal based on engagement we will need a better way to prove (or trust) payment receipts.
Randomizing Content
One of the most popular features we've rolled out on wavlake.com recently has been Wavlake Radio, a dynamically randomized playlist of everything on the site. In other words, mega-shuffle. It's a great way to discover new artists and music.
We decided to go all-in on this approach for Wavman. There is no song selection or search. All you can do is load up the player and see what you get.
The challenge is that a database (and a relay, for that matter) is not really built to return random results to you. They're great for retrieving data based on a key or set of filters, but when you ask it to shuffle a bunch of records like a deck of cards it has to do some obscure math and then simulate shuffling the deck.
Since we were already using uuid's to uniquely identify tracks on Wavlake, we decided to leverage that for Wavman's shuffle feature. We took the first character of the uuid and then set that as the value for an f tag ("filter") in the event. The f tag is not a standardized tag in Nostr at the time of this writing.
When requesting content, Wavman randomly picks a handful of possible values for that f tag and then uses that to filter results from the relay. For larger data sets in the future, a system like this could help clients sample events from relays more efficiently by using these kinds of tags, which are essentially applied distribution keys.
Relays vs Databases
A relay is a lot like a database, but also it’s not. One of the challenges of interacting with a relay is that your ability to efficiently filter and query the data using the available request parameters on Nostr is limited. For example, a client doesn’t have a great way to pull only songs by a particular artist from a relay. As it stands today, a client would have to get all the track events and then filter that result down to the artist we were interested in.
We do see potential in creating custom middleware for purposes like this that can make queries to relays more efficient – especially if the schema of the content is structured in a standard way. We could easily generate indexes for the values contained in these structures. Then, a client could send a request like “give me all the songs on this album” and the middleware could help fetch the right events for that query. It might be helpful in this case to have some kind of standard tag in the Nostr protocol that could be used as part of the request so a client could include a custom query filter for specific content schemas.
Other Considerations
Speaking of albums, you might have noticed we don't have a field for that in our initial NOM spec. This is because we think that data could just as easily exist in another, related, but different kind of document that contains a list of individual track events that comprise an album or a playlist. Because what is an album really but an artist's own playlist for a set of songs? If that artist ever wanted to update any tracks or change the ordering (á la Kanye's The Life of Pablo) they could do so per relevant event instead of having to update many events at once. In this case, a fan also could look back over the evolution of an album over time. There are, of course, trade-offs to normalizing data in this way. But we think keeping individual media events as self-contained as possible will allow for more composability on those events in the future.
Artist verification is another feature we're thinking a lot about. Of course, we need to get to a point where private key usage is more commonplace and the infrastructure more forgiving. Eventually, though, we do see a future where users will be able to verify not only an artist's identity but also the content that artist has signed and published. In an age when fakes, replicas, and AI-generated content are everywhere, this will be an important way for artists to control the quality of their material and ensure their fans can support them directly.
There is so much to think about when it comes to building for Nostr. It is incredibly simple on its surface, which is what makes it so approachable as a developer. But there are really interesting and complex challenges that come to light the deeper you go. And that is also part of its allure.
Special thanks
The Nostr community is pretty awesome. We're really grateful for the help and support we've received in the last few weeks through various channels. You all are great. In particular, special thanks to all the people behind nostr-tools, Nostream, Snort, and Iris.
All right, back to building.